Beyond SQuAD: How to Apply a Transformer QA Model to Your Data
A look at how transfer learning can boost performance in specialized domains.
- Specialized Domains
- Assessing a General QA model on Your Domain
- Experimenting with QA Domain Adaptation
- Practical Guidelines for Domain-Specific QA
- Final Thoughts
Implementing an IR QA system in the real-world is a nuanced affair. As we got deeper into our QA journey, we began to wonder: how well would a Reader trained on SQuAD2.0 perform on a real-world corpus? And what if that corpus were highly specialized - perhaps a collection of legal contracts, financial reports, or technical manuals? In this post, we describe our experiments designed to highlight how to adapt Transformer models to specialized domains, and provide guidelines for practical applications.

Photo by Morning Brew on Unsplash
Specialized Domains
Training a Transformer language model on the SQuAD dataset provides the model with the ability to supply short answers to general-knowledge, factoid-style questions. When considering more diverse applications, these models will perform well on similar question/answer types over text that is comparable in vocabulary, grammar, and style to Wikipedia (or general text media such as that found on the web) – essentially, text that is comparable to what the model was originally trained on. This encompasses a great many use cases.
For example, a QA system applied to your company’s general employee policies will likely be successful, as the text is typically not highly specialized or overly technical, and questions posed would most likely be fact-seeking in nature. (“When are the black out dates for company stock sales?” or “What building is Human Resources located in?”) In fact, this type of QA system could be viewed as a more sophisticated and intuitive internal FAQ portal.
Change either of these specs – question/answer type or text domain – and the accuracy of a SQuAD-trained QA model becomes less assured. It’s also important to note that neither of these characteristics are independent. Question type is intricately linked to answer type, and both can be heavily influenced by the style of text from which answers are to be extracted. For example, a corpus of recipes and cookbooks would likely be heavy on questions such as “How do I boil an egg?” or “When should I add flour?” – questions that typically require longer answers to explain a process.
Assessing a General QA model on Your Domain
Whether you know you have a specialized QA task or not, one sure-fire way to determine if your SQuAD-trained QA model is performing adequately is to validate it. In this blog series, we’ve demonstrated quantitative performance evaluation by measuring exact match (EM) and F1 scores on annotated QA examples. We recommend generating at least a few dozen to a couple hundred examples to sufficiently cover the gamut of question and answer types for a given corpus. Your model’s performance on this set can serve as a guide as to whether your model is performing well enough as-is or if it perhaps requires additional training. (Note: performance level should be set keeping in mind both the business need and the relative quality on the SQuAD dev set. For example, if your SQuAD-trained QA model is achieving an F1 score of 85 on the SQuAD dev set, it’s unrealistic to expect it to perform at 90+ on your specific QA task.)
Developing QA annotations can be a time-consuming endeavor. It turns out, though, that this investment can yield more than just a path to model validation. As we’ll see, we can significantly improve underperforming QA models by further fine-tuning them on a set of specialized QA examples.
Aiding in this endeavor are new tools that make QA annotation swift and standardized, like deepset’s Haystack Annotation. deepset is an NLP startup that maintains an open source library for question answering at scale. Their annotation application allows the user to upload their documents, annotate questions and answers, and export those annotations in the SQuAD format – ready for training or evaluation.

Once you have a dataset tailored to your use case, you can assess your model and determine whether additional intervention is warranted. Below, we’ll explain how we used an open-source domain-specific dataset to perform a series of experiments, in order to determine successful strategies and best practices for applying general QA models to specialized domains.
Experimenting with QA Domain Adaptation
You’ve trained your model on SQuAD and it can handle general factoid-style question answering tasks, but how well will it perform on a more specialized task that might be rife with jargon and technical content, or require long-form answers? Those are the questions we sought to answer. We note that, since these experiments were performed on only one highly specialized dataset, the results we demonstrate are not guaranteed in your use case. Instead, we seek to provide general guidelines for improving your model’s performance.
Domain-Specific QA Datasets
Research on general question answering has received much attention over the past few years, spurring the creation of several large, open-domain datasets such as SQuAD, NewsQA, Natural Questions, and more. QA for specialized domains has received far less attention - and thus, specialized datasets remain scarce, with the most notable open-source examples residing in the medical domain. These datasets typically contain a couple thousand examples. For our experiments, we combined two such datasets, which we briefly describe below.
BioASQ
BioASQ is a large-scale biomedical semantic indexing and question answering challenge organizer. Their dataset contains question and answer pairs that are created by domain experts, which are then manually linked to related science (PubMed) articles. We used 1504 QA examples that were converted into a SQuAD-like format by these authors. Their modified BioASQ dataset can be found here. (Note: registration is required to use BioASQ data.)
COVID-QA
This QA dataset, led by researchers at deepset, is based on the COVID-19 Open Research Dataset. It contains 2,019 question/answer pairs, annotated by volunteer biomedical experts. You can find the dataset here and learn more about it in their paper.
Dataset Characteristics
How is this dataset comparable to SQuAD? In this section, we highlight some of the key characteristics of our hybrid medical dataset.
Question Type
Here is a sample of questions from this medical dataset:
- Which gene is responsible for the development of Sotos syndrome?
- How many disulfide bridges has the protein hepcidin got?
- Which is the cellular localization of the protein Opa1?
- Which drug should be used as an antidote in benzodiazepine overdose?
- What is the main cause of HIV-1 infection in children?
- What is DC-GENR and where is it expressed?
- What is another name for IFITM5?
- What is the size of bovine coronavirus?
We see there are a lot of technical medical terms (“hepcidin,” “IFITM5”), as well as some more recognizable words (that likely have different implications or interpretations in a medical context - e.g., “localization,” “expressed”). However, the questions are overall generally factoids, similar to the SQuAD dataset. Below are the most common question types in the combined dataset.
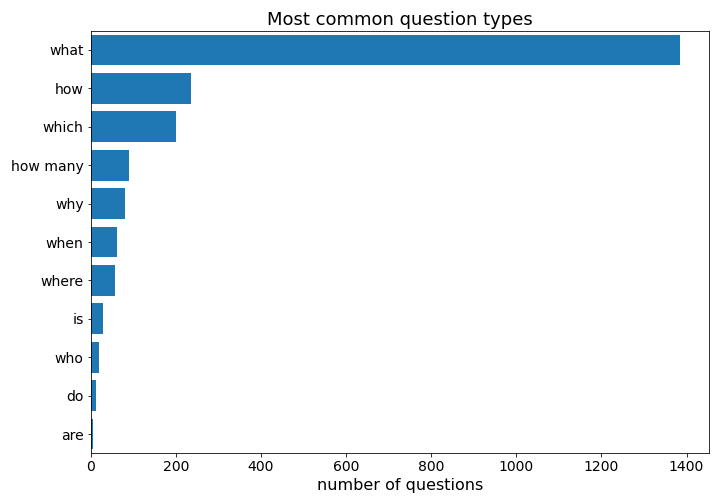
Context Length
While both datasets rely on scientific medical research articles for context, structure varies between them. The BioASQ contexts are subsections or paragraphs of research articles, while the COVID-QA contexts include the full research article. When combined, they yield a dataset with some very disparate context lengths.
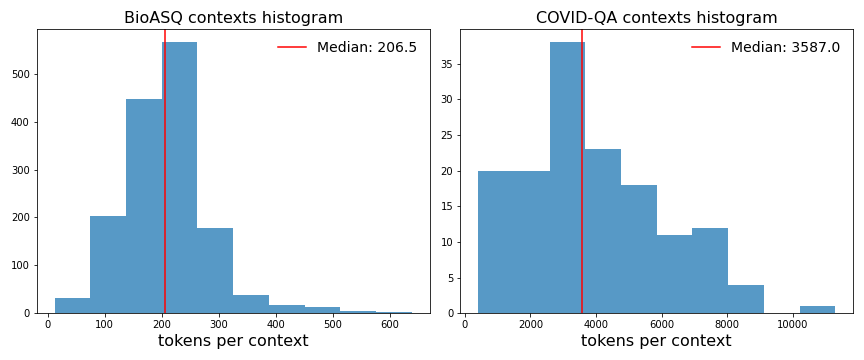
The BioASQ contexts contain an average of about 200 tokens, while the COVID-QA contexts contain 200 times that – an average of nearly 4000 tokens per context! This context length diversity is highly unlike SQuAD, and might be more indicative of a real-world dataset (since there is no reason to suspect uniform document length in any given corpus).
Answer Length
While the question types are similar to SQuAD, there are some stark differences in answer lengths. 97.6% of the answers in the BioASQ set consist of five or fewer tokens; this is very similar to SQuAD answer lengths. However, only 35% of answers in the COVID-QA set have fewer than five tokens, with the average at 14 tokens. Another full third of the answers are even longer than that - with the longest clocking in at 144 tokens! That’s basically a paragraph, and quite different from answers seen in the SQuAD dataset.
The combined medical datasets yield a total of 3523 QA examples. We pulled out 215 as a holdout (dev set), leaving us 3308 for training.
Standard Transfer Learning to a Specialized Domain
 A Transformer model first learns language modeling through semi-supervised training on massive corpora of unstructured text, such as Wikipedia and the web. (middle) That same model learns a specific task, such as question answering, by supervised training (fine-tuning) on the SQuAD dataset. (bottom) Additional fine-tuning on a set of specialized QA examples allows the same model to perform better question answering in a specific domain. At each stage, transfer learning ensures that fewer examples are necessary to improve on the next task, since the model can bootstrap from previously learned statistical relationships.")
If fine-tuning a pre-trained language model on the SQuAD dataset allowed the model to learn the task of question answering, then applying transfer learning a second time (fine-tuning on a specialized dataset) should provide the model some knowledge of the specialized domain. While this standard application of transfer learning is not the only viable method for teaching a general model specialized QA, it’s arguably the most intuitive (and simplest) to execute. However, we needed to take care during execution. We only had ~3300 examples for training, which is a far cry from the ~100k in the SQuAD dataset.
In a thorough analysis, we would perform a hyperparameter search over epochs, batch size, learning rate, etc., to determine the best set of hyperparameter values for our task - while being mindful of overfitting (which is easy to do with small training sets). However, even with a chosen, fixed set of hyperparameter values, research has shown that training results can vary substantially due to different random seeds. Evaluating a model through cross-validation allows us to assess the size of this effect. Unfortunately, both cross-validation and hyperparameter search (another cross-validation) are costly and compute-intensive endeavors.
In the practical world, most ML and NLP practitioners use hyperparameters that have (hopefully) been vetted by academics. For example, most people (including us) fine-tune on the SQuAD dataset, using the hyperparameters published by the original BERT authors. For this example, we used the hyperparameters published by the authors of the COVID-QA dataset. (While we combined their dataset with BioASQ, we felt these hyperparameters were nonetheless a good place to start.)
| Parameter | Value |
|---|---|
| language model | distilbert-base-uncased |
| general QA model | twmkn9/distilbert-base-uncased-squad2 |
| batch size | 80 |
| epochs | 2 |
| learning rate | 3e-5 |
| max seq len | 384 |
| doc stride | 192 |
| cross val folds | 5 |
Note: We continued to use DistilBERT, because it’s lightweight and quick to train. However, it’s also known that DistilBERT doesn’t perform as well as BERT or RoBERTa for QA. Fortunately, in this case, we cared more about relative performance gains than absolute performance.
We started by exploring three things:
- whether fine-tuning on a small specialized dataset improves performance on specialized question answering;
- if so, which strategy provides the best performance gain;
- and what relative improvement we should expect.
We used DistilBERT trained on SQuAD as our General QA Model. We evaluated this model on our medical holdout set to gain a performance baseline (blue bar). Next, we trained a Specialized QA Model by fine-tuning the General Model on the medical train set, using the hyperparameters above. The performance of the Specialized Model on the medical holdout set is shown in the below figure by the orange bars. Transfer learning through additional fine-tuning on the medical dataset resulted in nearly ten point increases in both EM and F1 scores - a considerable improvement!
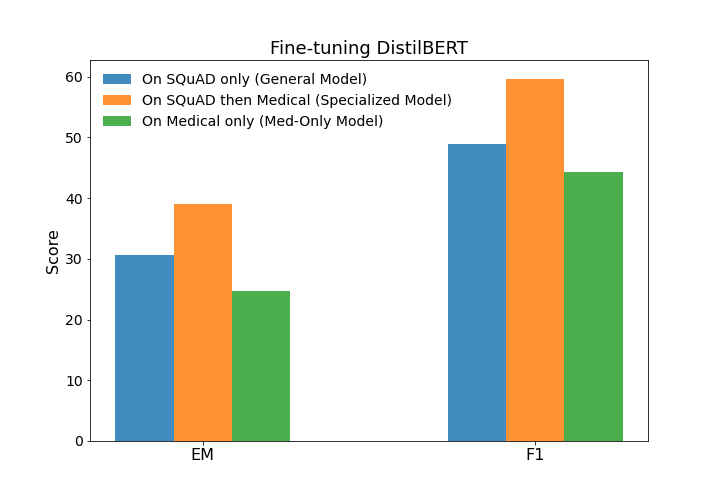
Was it really necessary to start with a General QA Model that had already been fine-tuned on SQuAD? Perhaps we could have simply started with a pre-trained language model – a model that had not yet been trained at any explicit task – and fine-tuned directly on the medical dataset, essentially teaching the model both the task of question answering and the specifics of the specialized dataset at the same time.
The green bars in the graphic above show the results of training the language model (listed in the table above) directly on our medical dataset. We’ll call this the Med-Only Model. As expected, it performed worse than either the General Model or our Specialized Model, but not by much! The blue and green bars differ by a only couple points - which is surprising, since the General Model is trained on 100k general examples and the Med-Only Model is trained on only 3300 specialized examples. This demonstrates that it’s not only a numbers game; it’s just as important to have data that reflects your specific domain.
But how many specialized examples are enough? Training the General Model on an additional 3300 specialized question/answer pairs achieved about a ten point increase in F1. Because generating QA annotations is costly, could we have done it with fewer examples? We explored this by training the General Model model on increasing subsets of the medical train set, from 500 to 3000 examples. With only 500 examples we saw a four-point relative F1 increase. F1 increased rapidly with increasing training examples until we hit a training size of about 2000 examples, after which we saw diminishing returns on further performance gains.
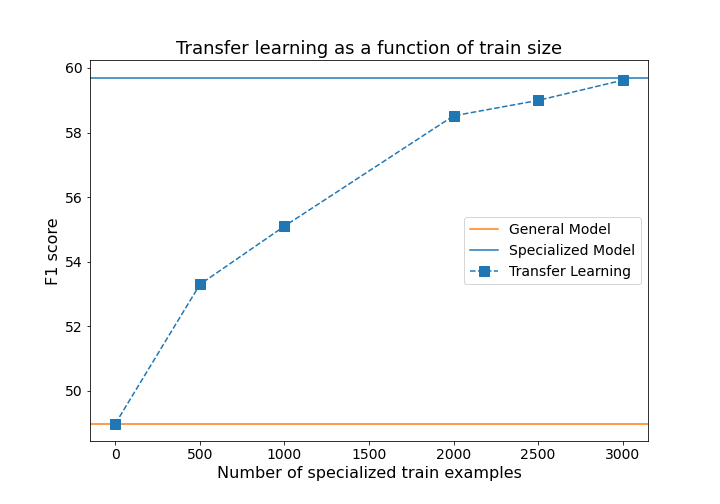
This highlights a common tradeoff between model improvement and development cost. Of course, with infinite resources, we can train better models. However, resources are almost always limited, so it’s encouraging to see that even a small investment in QA annotation can lead to substantial model improvements.
How robust are these results? As a final check, we performed a five-fold cross-validation training, wherein we kept all hyperparameters fixed but allowed the random seed and training order to vary. Below we see that the results were fairly robust, with a spread of about three to four points in either F1 or EM, which is far smaller than the ten point increase we saw when going from our General Model to the Specialized Model. This indicates that the performance gain is a real signal. (This figure was inspired by a similar one in this paper.)

With that said, we again stress that the performance we’ve demonstrated here is not guaranteed in every QA application to a specialized domain. However, our experiments echo the findings of other studies in the literature, which is heartening.
To learn more, check out the following papers:
As a result of our experiments, we believe that the following are a solid set of guidelines for practical QA applications in specialized domains.
Practical Guidelines for Domain-Specific QA
- General QA Models will provide solid performance in most cases, especially for QA tasks that require answering factoid questions over text that is qualitatively similar to Wikipedia or general text content on the web.
- Applying a General QA Model in a specialized domain may benefit substantially from applying transfer learning to that domain.
- Utilizing standard transfer learning techniques allows practitioners to leverage currently existing QA infrastructure and libraries (such as Hugging Face Transformers or deepset’s haystack). 4, Generating annotations for specialized QA tasks can thus be a worthwhile investment, made easier with emerging annotation applications. 5, A substantial performance increase can be seen with only a few hundred specialized QA examples, and even greater gains achieved with a couple thousand.
- Absolute performance will depend on several factors, including the chosen model, the new domain, the type of question, etc.
Final Thoughts
Question answering is an NLP capability that is still emerging. It currently works best on general-knowledge, factoid-style, SQuAD-like questions that require short answers. This type of QA lends itself well to use cases such as “enhanced search” – allowing users to more easily and intuitively identify not just documents or websites of interest, but explicit passages and sentences, using natural language. There is no question that this style of QA is closest to maturity.
However, research continues to accelerate, as new models and datasets emerge that push the boundaries of SQuAD-like QA. Here are two areas we’re watching closely:
- QA models that combine search over large corpora with answer extraction, because as we saw in this blog series, your Reader is limited by the success of your Retriever (more on that in this blog post)
- QA models that can infer an answer based on several pieces of supporting evidence from multiple documents. This is a task that, in essence, marries QA with Text Summarization.
In the meantime, there is still much to be done with standard QA, and we’d love to hear about your use cases! This will be the final blog post for this particular series, and we hope you’ve enjoyed the ride. We learned a lot, and have been thrilled to share our exploration.